It’s pretty difficult to escape recommender systems in 2024. These days, we regularly get recommended things such as content from streaming services like Netflix and products from online shopping platforms like Amazon. Even if you don’t know the term recommender systems, there’s a good chance you understand what it does.
I first heard about recommender systems in the context of the Netflix prize which was an open competition in 2009 for best collaborative filtering (CF) algorithm. The challenge was to improve upon Netflix’s existing recommender system by at least 0.10 RMSE and the winner was awarded $1MM. Around that time, nearest neighbor techniques were popular CF methods however, the winners of the Netflix prize proved that matrix factorization (MF) models were superior. MF models have some similarity to singular value decomposition (SVD) but can handle sparsity often seen with recommender system datasets whereas SVD can’t.
To understand more about MF and recommender systems, in this post I’ll be creating an algorithm from scratch and evaluating it’s performance on the MovieLens dataset (see here for more info). In particular, I’ll be implementing probabilistic matrix factorization (PMF) which was a seminal improvement over previous MF techniques because of it’s ability to handle sparsity and scale linearly with data (see paper here).
Intuition
Before diving into a mathematical derivation, let me provide some intuition about how MF works.
In a ratings scenario we have some number of n users and m movies. This can be represented with an n x m matrix where values of the matrix are the ranking a person gave to a movie. For simplicity, let’s say the value is a 1 if they watched and liked the movie otherwise it’s a 0. Most people will only watch a handful of movies so there’ll be many missing values in the matrix.
In the ratings matrix, each user can be described by the sparse vector of 1’s (mostly 0’s) that indicate the movies they liked (or the users that liked them in the case of movie vectors). But we can use a more compact representation similar to how one-hot encoded words are condensed via word embeddings. This allows for better comparison if we want to use something like cosine similarity to compare users, for example.
The dense representations of users and movies will form two smaller matrices, an n x d user matrix and an m x d movie matrix where d << n and d << m. You can see from a quick dimensionality analysis that the product of these two smaller matrices could be an approximation for the original ratings matrix.
In fact, we could minimize the difference between the approximation and the true rating in an optimization process. Once we’ve done that, we would even have an estimate of the rating a user might have given a movie even if they didn’t watch it. And the movie with the highest likelihood of a positive rating, well we can recommend that to a user. So at a high level, that’s exactly what I’m going to do here with MF.
MAP and Objective Function
Time for more formal mathematical definitions. Like I mentioned above, we have \(n\) users and \(m\) movies as well as a ratings matrix \(R \in \mathbb{R}^{n \times m}\) such that \(R_{i,j}\) is the rating by user \(i\) for movie \(j\). The user latent matrix is \(U \in \mathbb{R}^{d \times n}\) and movie latent matrix \(V \in \mathbb{R}^{d \times m}\) where \(d\) is the latent space dimension and a tunable hyperparameter.
The author’s of the paper make an assumption on the distribution of \(R_{i,j}\), which is the product of latent vectors \(U_i\) and \(V_j\).
And the latent vectors \(U_i\) and \(V_j\) are also assumed to be normally distributed with zero mean and spherical covariance (dimensionality \(d\)). You don’t always hear this term “spherical covariance” but it essentially means all dimensions are independent with same mean and variance (i.e. IID). The variance is also tunable via the \(\lambda\) parameter (defined further below).
\[U_i \sim N(0, \sigma_u ^ 2 \mathbf{I})\]
\[V_j \sim N(0, \sigma_v ^ 2 \mathbf{I})\]
Now we can define the likelihood function for the entire ratings matrix
In a previous post I went through a process to derive a MAP estimate. This is similar. Here we can also approximate the posterior by the product of the likelihood and priors
and because summations are easier to work with than products, we take the log of the posterior (see paper for details) and maximize that to derive the MAP solution. After some re-arranging for a minimization objective, we would arrive at the following objective function as described in the paper.
where \(I_{i,j}\) is an indicator function if user \(i\) has rated movie \(j\), and \(\lambda_u = \frac{\sigma^2}{\sigma_u^2}\) and similarly \(\lambda_v = \frac{\sigma^2}{\sigma_v^2}\). The indicator function is an important addition in the objective function as it allows us to ignore the vast number of unrated movies for each user.
An interesting aside here is that the priors are essentially adding L2 regularization terms in the objective function. If we were to maximize the likelihood only (i.e. MLE) we wouldn’t have these terms.
Ok, so the paper gets us to this objective function but leaves out any description of a learning algorithm. So now we have to derive update rules in order to learn values for \(U\) and \(V\).
Derivation of Learning Algorithm
If you look at the objective function, you’ll see we have two unknown latent matrices \(U\) and \(V\). Because of this, the objective function is not convex. However, if one of the matrices is fixed, then the other turns into a convex optimization problem. So we can take turns with updates to \(U\) and \(V\) by performing an alternating coordinate descent. Note that in this context it is also referred to least squares optimization (ALS). These links by Facebook and Google were helpful for confirming this important optimization detail.
To find the update rules, we need to derive partial derivatives for \(U_i\) and \(V_j\) with respect to the objective function. So, time to dive into a little matrix calculus with a derivation for \(\frac{\partial E}{\partial U_i}\).
There is another interesting aside here about the priors. If we were to do MLE instead of MAP we’d get a similar update rule except for the \(\lambda_v \mathbf{I}\) term. If you’ve ever tried to implement your own least squares solution in closed form, you may remember that regression coefficients require inverting the matrix \((X^\intercal X)^{-1}\). Sometimes your data doesn’t behave well and you end up with a non-invertible matrix (because your determinant is zero). The \(\lambda_v \mathbf{I}\) term is essentially adding some values to the diagonal of the matrix which makes it less likely to have a zero determinant (i.e. more stable).
Ok, so armed with these update rules now we can dive into some code.
# sanity check - all movies have rating and all users have rated as expectedusers_not_rated = np.all(np.isnan(R), axis=1).sum()movies_not_rated = np.all(np.isnan(R), axis=0).sum()assert0== users_not_rated == movies_not_rated
# ratio missing valuesn, m = R.shapenans = np.isnan(R).sum()num_ratings = m * n - nansprint(f"total number of users: {n}")print(f"total number of movies: {m}")print(f"total number of movie ratings: {num_ratings}")print(f"total number of possible ratings: {n * m}")print(f"missing values in ratings matrix: {100*round(nans / (m * n), 3)}%")
total number of users: 69878
total number of movies: 10677
total number of movie ratings: 10000054
total number of possible ratings: 746087406
missing values in ratings matrix: 98.7%
# indices of ratingsrating_idxs = np.argwhere(np.isfinite(R)) # 2D array [[i ,j], ...]# randomly select 15% of rating indices to keep as testtrain_slice = np.random.choice(num_ratings, size=int(num_ratings *0.85), replace=False)test_slice = np.setdiff1d(np.arange(num_ratings), train_slice)train_idxs = rating_idxs[train_slice, :]test_idxs = rating_idxs[test_slice, :]train_idxs.shape, test_idxs.shape
((8500045, 2), (1500009, 2))
Training and Evaluation
# fill test indices with nan in training dataR_train = R.copy()for i, j in test_idxs: R_train[i, j] = np.nanassert np.isnan(R_train).sum() == nans + test_idxs.shape[0]
# normalizing the training data to zero mean and sigma of 1 for simplicityii_train = train_idxs[:, 0].flatten()jj_train = train_idxs[:, 1].flatten()R_train_mu = R_train[ii_train, jj_train].mean()R_train_sigma = R_train[ii_train, jj_train].std()R_train = (R_train - R_train_mu) / R_train_sigmaprint(f"R train mu: {round(R_train_mu, 2)}\t R train sigma: {round(R_train_sigma, 2)}")
R train mu: 3.51 R train sigma: 1.06
# paper uses:# d=30 with original netflix dataset 100M+ ratings, ~500k users, ~20k movies# adaptive prior w/ spherical covariances lambda U = 0.01, lambda V = 0.001# constrained PMF lambda = 0.002d =30lambda_u =20# higher better, just some random experimentation herelambda_v =20sigma_r =1# normalized above, else: np.std(R[~np.isnan(R)])sigma_u = np.sqrt(sigma_r**2/ lambda_u)sigma_v = np.sqrt(sigma_r**2/ lambda_v)# randomly generate values for user and movie latent matrices# U can be empty since updated firstU_mu = np.zeros(d)U_cov = np.identity(d) * sigma_u**2# sphericalU = np.random.multivariate_normal(U_mu, U_cov, size=n).TV_mu = np.zeros(d)V_cov = np.identity(d) * sigma_v**2V = np.random.multivariate_normal(V_mu, V_cov, size=m).T# D x M/NU.shape, V.shape
((30, 69878), (30, 10677))
# function to update U_i latent vectordef update_U_i(i, ratings_matrix, user_matrix, movie_matrix, lambda_u):# valid j (i.e. movies this user rated) j_idxs = np.argwhere(np.isfinite(ratings_matrix[i, :])).flatten()# skip if no movies rated in train setiflen(j_idxs) ==0:return# running summation sum_rv = np.zeros(d) # vector: weighted V_j by R_ij sum_vv = np.zeros((d, d)) # matrix: outer product V_jfor j in j_idxs: V_j = movie_matrix[:, j] sum_rv += V_j * ratings_matrix[i, j] sum_vv += np.outer(V_j, V_j) user_matrix[:, i] = sum_rv @ np.linalg.inv(sum_vv + np.identity(d) * lambda_u)def update_V_j(j, ratings_matrix, user_matrix, movie_matrix, lambda_v):# valid i (i.e. users that rated this movie) i_idxs = np.argwhere(np.isfinite(ratings_matrix[:, j])).flatten()# skip if no users rated in train setiflen(i_idxs) ==0:return sum_ru = np.zeros(d) # vector: weighted U_i by R_ij sum_uu = np.zeros((d, d)) # matrix: outer product U_ifor i in i_idxs: U_i = user_matrix[:, i] sum_ru += U_i * ratings_matrix[i, j] sum_uu += np.outer(U_i, U_i) movie_matrix[:, j] = sum_ru @ np.linalg.inv(sum_uu + np.identity(d) * lambda_v)
# use logistic function since ratings prediction is zero mean (same as paper)def sigmoid(x):return1/ (1+ np.exp(-x))# paper maps sigmoid to range [1, 5] but movielens [0.5, 5]def sigmoid_to_rating(x, min_rating=0.5, max_rating=5):return (max_rating - min_rating) * x + min_rating
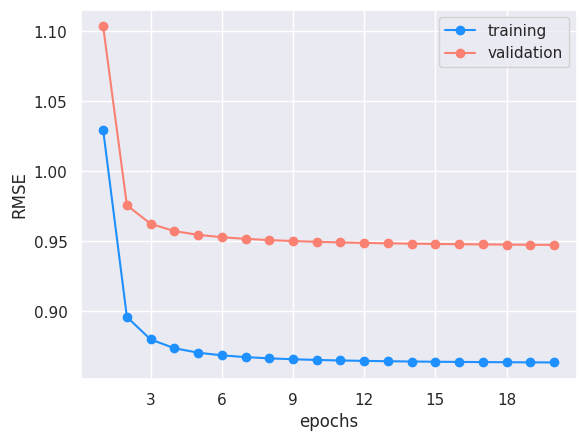
# run optimization and report RMSEepochs =20train_rmse = []valid_rmse = []lambda_u_hat = lambda_ulambda_v_hat = lambda_vfor e inrange(epochs):for i inrange(n): update_U_i(i, R_train, U, V, lambda_u_hat)for j inrange(m): update_V_j(j, R_train, U, V, lambda_v_hat)# adaptive... single sigma -> update lambda_uv = 1 / (sigma_uv ** 2)# TODO paper updates priors every 10 feature matrix updates# sigma_u_hat = np.std(U)# sigma_v_hat = np.std(V)# lambda_u_hat = 1.0 / ((sigma_u_hat ** 2) + 1e-9) # small epsilon to avoid zero division error# lambda_v_hat = 1.0 / ((sigma_v_hat ** 2) + 1e-9)# print(f"sigma U: {sigma_u_hat}")# print(f"sigma V: {sigma_v_hat}")# print(f"lambda u: {lambda_u_hat}")# print(f"lambda v: {lambda_v_hat}")# training metrics sse =0 sse_norm =0for i, j in train_idxs: # skips NA r_ij_hat = np.dot(U[:, i], V[:, j]) # pred rating = sigmoid_to_rating(sigmoid(r_ij_hat)) sse += (R[i, j] - rating) **2 sse_norm += (R_train[i, j] - r_ij_hat) **2 rmse_train = np.sqrt(sse / train_idxs.shape[0]) rmse_norm = np.sqrt(sse_norm / train_idxs.shape[0])print(f"epoch {e +1} | training RMSE: {round(rmse_train, 4)} (normalized: {round(rmse_norm, 4)})") train_rmse.append(rmse_train)# validation RMSE sse =0for i, j in test_idxs: r_ij_hat = np.dot(U[:, i], V[:, j]) rating = sigmoid_to_rating(sigmoid(r_ij_hat)) sse += (R[i, j] - rating) **2 rmse_valid = np.sqrt(sse / test_idxs.shape[0])print(f"epoch {e +1} | validation RMSE: {round(rmse_valid, 4)}") valid_rmse.append(rmse_valid)
The best validation RMSE we get after 20 epochs is 1.092. While the baseline RMSE that Netflix had achieved before the competition was 0.95, this isn’t an apples to apples comparison. The MovieLens dataset is different with ratings that go down to 0.5 and in increments of 0.5 whereas the Netflix dataset had a range of [1, 5] and in whole number increments.
This was mostly an exercise in understanding PMF with the challenge of deriving and implementing the algorithm starting from the objective function shown in the research paper. But, if we wanted to squeeze out more performance there are several things we could do:
use adaptive covariance (biggest gains)
tune the lambda regularization coefficients (I started with 1 and only went up/down by an order of magnitude)
separate covariances for users and movies
diagonal covariance matrix (instead of spherical) to account for different variation between latent features
Even though we didn’t go through the most rigorous optimization process here, let’s see if any of the predictions make sense. I’ll pick a random user, see what they like in the test set, then compare that to what would get recommended to them.
# map internal ratings matrix movie IDs back to actual MovieLens IDs# pivot causes some IDs to be skippedratings_id_to_movie_id = {idx: i for idx, i inenumerate(np.sort(ratings_df['movieId'].unique()))}assertlen(ratings_id_to_movie_id) == R.shape[1] # sanity checkmovie_id_to_title =dict(zip(movies_df.movieId, movies_df.title))movie_id_to_genre =dict(zip(movies_df.movieId, movies_df.genres))
# what random user likes in testtest_rating_thresh =4.0test_user_id = np.random.choice(np.unique(test_idxs[:, 0]))# test_user_id = 32328test_user_existing_ratings_idxs = test_idxs[test_idxs[:, 0] == test_user_id][:, 1]print(f"User {test_user_id} liked the following movies in the test set:", "\n")for j in test_user_existing_ratings_idxs:if R[test_user_id, j] >= test_rating_thresh: movie_id = ratings_id_to_movie_id[j] title = movie_id_to_title.get(movie_id, "Unknown Title") genre = movie_id_to_genre.get(movie_id, "Unknown Genre") rating = R[test_user_id, j]print(f"Title: {title}\nGenre: {genre}\nRating: {rating}\n")
User 18001 liked the following movies in the test set:
Title: Much Ado About Nothing (1993)
Genre: Comedy|Romance
Rating: 4.0
Title: 2001: A Space Odyssey (1968)
Genre: Adventure|Sci-Fi
Rating: 4.0
Title: American Beauty (1999)
Genre: Drama
Rating: 4.0
Title: Fight Club (1999)
Genre: Action|Crime|Drama|Thriller
Rating: 4.0
Title: Mulholland Drive (2001)
Genre: Crime|Drama|Film-Noir|Mystery|Thriller
Rating: 4.0
Title: Amelie (Fabuleux destin d'Amélie Poulain, Le) (2001)
Genre: Comedy|Romance
Rating: 4.0
Title: Count of Monte Cristo, The (2002)
Genre: Drama|Thriller
Rating: 4.5
Title: Lord of the Rings: The Two Towers, The (2002)
Genre: Action|Adventure|Fantasy
Rating: 4.5
Title: Kill Bill: Vol. 1 (2003)
Genre: Action|Crime|Thriller
Rating: 5.0
Title: Big Fish (2003)
Genre: Drama|Fantasy|Romance
Rating: 4.5
Title: Lord of the Rings: The Return of the King, The (2003)
Genre: Action|Adventure|Fantasy
Rating: 4.5
Title: Bourne Ultimatum, The (2007)
Genre: Action|Adventure|Mystery|Thriller
Rating: 4.0
# generate predictions for all moviestest_user_vector = U[:, test_user_id]test_user_pred_scores = np.dot(test_user_vector, V)test_user_pred_ratings = sigmoid_to_rating(sigmoid(test_user_pred_scores))# filter out any already rated in train set by setting rating to -1already_rated = np.argwhere(np.isfinite(R_train[test_user_id, :])).flatten()test_user_pred_ratings[already_rated] =-1# recommend highest rated kk =10rec_idxs = np.argsort(test_user_pred_ratings)[-k:][::-1]# print(test_user_pred_ratings[rec_idxs])print(f"Top {k} recommendations for user {test_user_id}:", "\n")for rec_id in rec_idxs: pred_rating =round(test_user_pred_ratings[rec_id], 2) movie_id = ratings_id_to_movie_id[rec_id] title = movie_id_to_title.get(movie_id, "Unknown Title") genre = movie_id_to_genre.get(movie_id, "Unknown Genre")print(f"Title: {title}\nGenre: {genre}\nPredicted Rating: {pred_rating}\n")
Top 10 recommendations for user 18001:
Title: Natural Born Killers (1994)
Genre: Action|Crime|Thriller
Predicted Rating: 4.17
Title: Kill Bill: Vol. 1 (2003)
Genre: Action|Crime|Thriller
Predicted Rating: 4.08
Title: Fight Club (1999)
Genre: Action|Crime|Drama|Thriller
Predicted Rating: 3.94
Title: Seven (a.k.a. Se7en) (1995)
Genre: Crime|Horror|Mystery|Thriller
Predicted Rating: 3.93
Title: Godfather: Part II, The (1974)
Genre: Crime|Drama
Predicted Rating: 3.9
Title: Schindler's List (1993)
Genre: Drama|War
Predicted Rating: 3.79
Title: Lord of the Rings: The Return of the King, The (2003)
Genre: Action|Adventure|Fantasy
Predicted Rating: 3.68
Title: Goodfellas (1990)
Genre: Crime|Drama
Predicted Rating: 3.66
Title: American History X (1998)
Genre: Crime|Drama
Predicted Rating: 3.63
Title: Lord of the Rings: The Two Towers, The (2002)
Genre: Action|Adventure|Fantasy
Predicted Rating: 3.62
We can see some of the top recommended movies are actually movies that the user rated highly in the test set (unseen during training), so some of our predictions are making sense here. Some of the other recommendations also appear to have a genre overlap with what the user likes.